At Encinitas 3D, we’re always exploring new ways to merge data, creativity, and technology. Estuary was born out of that drive—a quiet but powerful system designed to feed our machine learning projects with rich, diverse, and continuous data.
The concept started simple: so much valuable data exists in public APIs, imagery, web feeds, and open datasets, but it’s scattered and rarely structured in a way that makes sense for machine learning. Real-time access is easy, but what about the historical context needed to detect trends and train accurate predictive models? That’s where Estuary comes in.
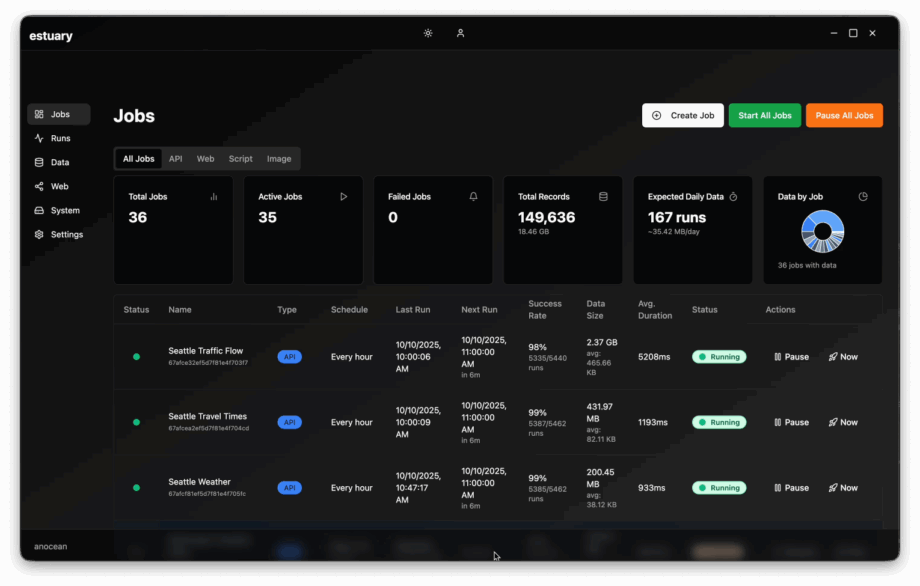
Estuary continuously gathers and organizes digital content from a variety of sources, from weather and traffic data to event schedules and satellite imagery. It does this just-in-time (JIT), but also stores and structures the historical layers that reveal long-term patterns. This foundation enables us to train models that not only react to the present moment but also anticipate what’s next.
We’re currently applying Estuary’s pipeline to public data in the Seattle area in partnership with local events and sports organizations. The system ingests, cleans, and standardizes information, then makes it trivially easy to inject into our data science workflows. Whether the goal is predicting crowd flow, identifying correlations between weather and attendance, or training geospatial forecasting models, Estuary provides the structured foundation every ML system needs.
What makes Estuary special isn’t flash—it’s reliability. It’s been running 24/7 for nearly a year, battle-tested by our teams, and has proven itself a cornerstone of our data infrastructure. Think of it as the tide beneath the surface: steady, consistent, and essential.
As we continue expanding Estuary’s reach, the goal remains the same—turning the constant stream of available data into something meaningful, insightful, and ultimately transformative for how we understand and predict the world around us.